Why do we need Latches?
Latches were first introduced in SQL Server 7.0, when Microsoft first introduced row-level locking. For row-level locking it was very important to introduce a concept like latching, because otherwise it would give rise to phenomena like Lost Updates in memory. As I have stated above, a latch is a lightweight synchronization object used by the Storage Engine to protect memory structures used internally by SQL Server. A latch is nothing more than a so-called Critical Section in multi-threaded programming – with some differences.
In traditional concurrent programming, a critical section is a code path, which must always run single-threaded – with only one thread at a time. A latch itself is a specialized version of a critical section, because it allows multiple concurrent readers. In the context of SQL Server this means that multiple threads can concurrently read a shared data structure, like a page in memory, but writing to that shared data structure must be performed single-threaded.
A latch is used to cordinate the physical execution of multiple threads within a database, whereas a lock is used on a logical level to achieve the required isolation based on the chosen isolation level of the transaction. You, as a developer or DBA, can influence locks in some ways – e.g. through the isolation level, or also through the various lock hints that are available in SQL Server. A latch on the other hand, can’t be controlled in a direct way. There are no latch hints in SQL Server, and there is also no latch isolation level available. The following table compares locks and latches against each other.

As you can see from that table, latches also support more fine grained modes like Keep and Destroy. A Keep latch is mainly used for reference counting, e.g. when you want to know how many other latches are waiting on a specific latch. And the Destroy latch is the most restrictive one (it even blocks the KP latch), which is used when a latch is destroyed, e.g. when the Lazy Writer wants to free up a page in memory. The following table gives you an overview of the latch compatibility matrix in SQL Server.

In the following short flipchart demo, I want to show you why latches are needed in SQL Server, and which phenomena would happen without them.
As you have seen in the previous flipchart demo, consistency can’t be achieved in SQL Server with locking alone. SQL Server still has to access shared data structures that are not protected by the lock manager, like the page header. And even other components within SQL Server that have single-threaded code paths are built on the foundation of latches. Let’s continue therefore now with the various latch types in SQL Server, and how you can further troubleshoot them.
Latch Types & Troubleshooting
SQL Server distinguishes between 3 different types of latches:
- IO Latches
- Buffer Latches (BUF)
- Non-Buffer Latches (Non-BUF)
Let’s have a more detailed look at these 3 different variations.
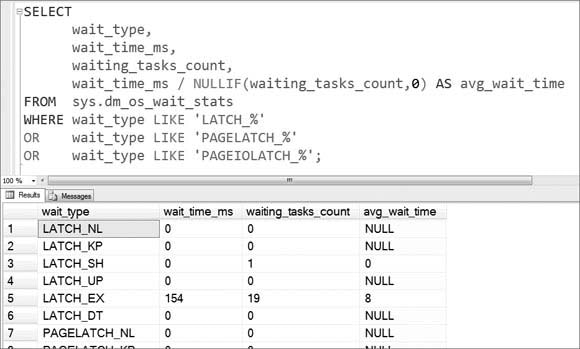
I/O Latches are used by SQL Server when outstanding I/O operations against pages in the Buffer Pool are done – when you read and write from/to your storage subsystem. For these I/O latches SQL Server reports a wait type that starts with
PAGEIOLATCH_. You can see the waiting times introduced with these types of latches in the DMV
sys.dm_os_wait_stats in the following picture.

With these latches SQL Server makes sure that pages are not read concurrently multiple times into the buffer pool, and that pages are not discarded from the buffer pool, when they are currently accessed by a query. In addition to the I/O latches SQL Server also supports so-called
Buffer Latches, which are used to protect the pages in the buffer pool from concurrent running threads. These are the latches that SQL Server uses to prevent
Lost Updates in memory, as I have demonstrated in the previous flipchart demo. Without these kinds of latches, it would be possible to read and write a page concurrently in the buffer pool, which would give rise to corruption of the pages in main memory. SQL Server also reports the waits introduced by these latches with wait types starting with
PAGELATCH_*. These wait types are again reported to you through the DMV
sys.dm_os_wait_stats. The most important thing here is that you hit contention in main memory, when there is not the term
IO in the wait type name.

And finally SQL Server internally uses so-called
Non-Buffer Latches to protect shared data structures besides the buffer pool itself. SQL Server also reports these latches in the DMV
sys.dm_os_wait_stats with wait types starting with
LATCH_.

But the waits reported in this DMV for Non-Buffer Latches are just a summary view of all individual latches that SQL Server uses internally. You can find a further breakdown of the individual latches in a separate DMV –
sys.dm_os_latch_stats:

SQL Server 2014 internally uses 163 latches to synchronize access to shared data structures. One prominent latch is
FGCB_ADD_REMOVE, which protects the so-called File Group Control Block (FGCB) of a file group during certain operations like:
- File growth (manually & automatically)
- Adding/dropping a file from a file group
- Recalculating proportional fill weightings
- Cycling through a files of a file group during the round-robin allocation
When you see high waits on that specific latch, you mainly have problems with too many auto growth operations, and therefore bad default settings of your database. When a query tries to read/write a protected data structure and has to wait for a latch, the query is always put into the suspended state, and has to wait until the latch can be acquired successfully. Therefore the query always goes through the complete query life cycle consisting of the states
RUNNING,
SUSPENDED,
RUNNABLE, and finally
RUNNING again. For that reason, enforcing the protection of a shared data structure only makes sense when the query holds the latch for a long time. That is because changing the state of the query also means performing a context switch in the Windows OS, which is a very expensive operation in terms of introduced CPU cycles.
Therefore it doesn’t make sense to put a latch in front of a shared data structure which will be read or written very frequently and only for a very short amount of time. In that case the needed context switches will kill the overall performance of SQL Server, and it would take too much time to go through the complete query life cycle (
RUNNING,
SUSPENDED,
RUNNABLE). That’s the area where SQL Server introduces so-called
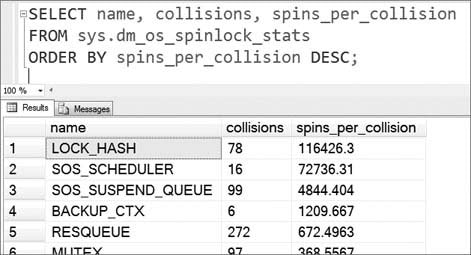
Spinlocks. The Lock Manager is a good example of such a data structure: it needs single-threaded access when locking and unlocking data items (like a record, a page, etc.). But when you look at
sys.dm_os_latch_stats, you will find no latch that protects the Lock Manger itself. The corresponding hash bucket in the hashtable used by the Lock Manager is protected by a spinlock – the
LOCK_HASH spinlock. The spinlock must be acquired before executing a lock or unlock operation through the Lock Manager. But today I am not going to talk about spinlocks, because I plan a dedicated blog posting just about them – so you will have to wait for that:-)
Summary
In this blog posting we have looked at latches in SQL Server. As you have seen latches are lightweight synchronization objects used by SQL Server to protect shared data structures in memory. SQL Server distinguishes between 3 different types of latches – IO Latches, Buffer Latches, and Non-Buffer Latches. You have also seen how you can troubleshoot latch waits with DMVs like
sys.dm_os_wait_stats and
sys.dm_os_latch_stats.

{kind=link}